What I Think is Wrong with Whiskey Reviews
================
What I Think is Wrong with Whiskey Reviews
The whiskey review system is broken
For reason’s I’m going to argue below, I think the current 1-100 whiskey review system is absolute garbage. It’s weak, uninformed, and if it were a person - it would be the kind of asshole thinks Old Weller Antique is a ‘unicorn’.
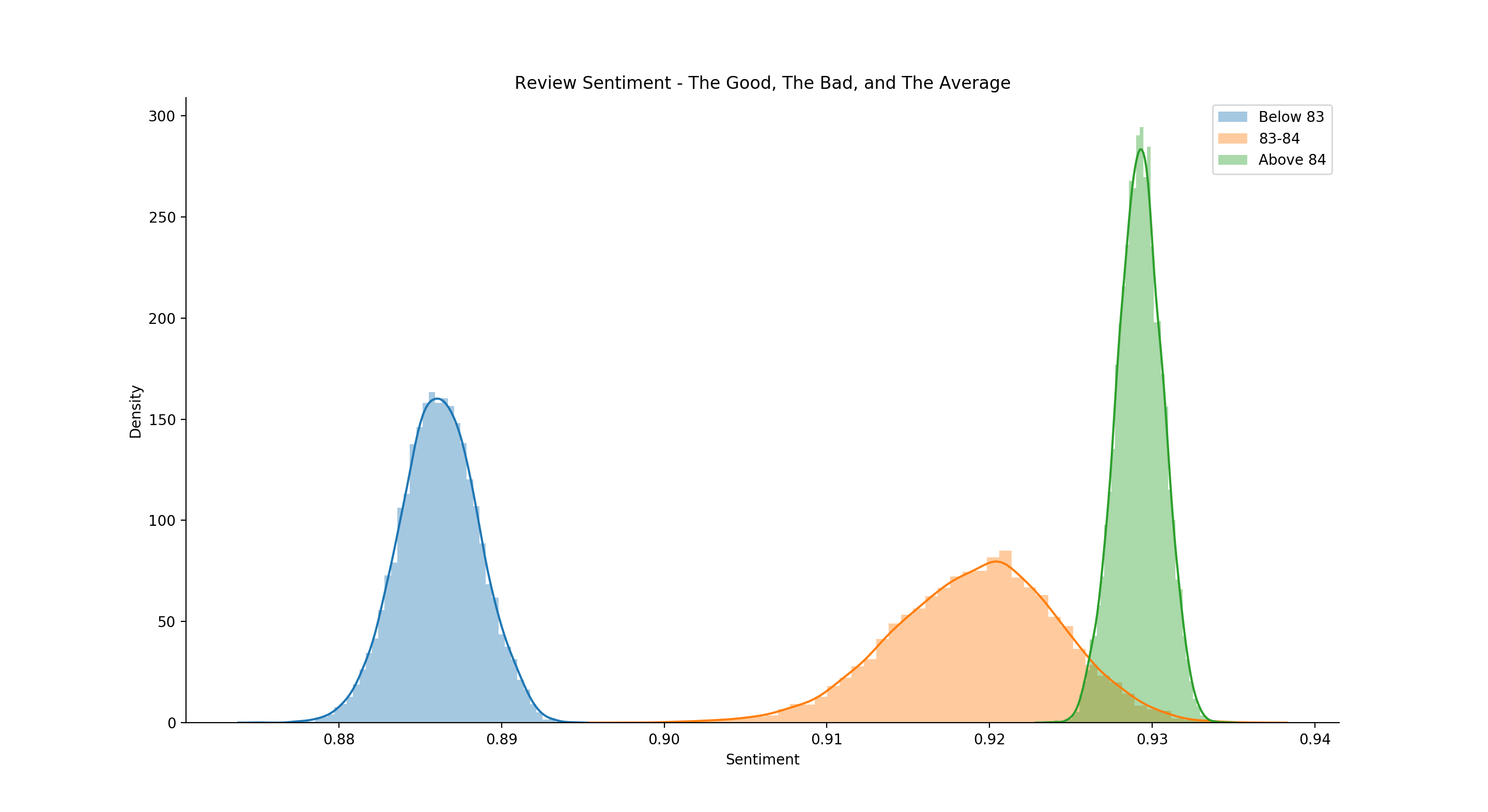
With insults out of the way, let’s dive right in and take a look at what an ‘average’ review looks like on reddit. In order to do so, we’ll use a technique called Bayesian Bootstrapping to resample our review data many times in such a way to provide an estimate of where the ‘true’ mean of the data may lie. This technique, in typical bayesian fashion, yields a distribution rather than a point estimate and doing so allows us to place our confidence on a range of numbers rather than a singular value. What are the benefits of this? Well, it allows us to hedge our ‘wrongness’ or ‘rightness’ (depending on what your outlook is) on a set of numbers rather than placing the whole kit and caboodle on one value. It allows us to view the world in a probalistic sense, meaning that there’s a high probability that our true mean lies within the distribution we’ve created. Using this technique, we can we can say that the true mean review score lies somewhere between 83.77 and 84.09.
import matplotlib.pyplot as plt
import seaborn as sns
import bayesian_bootstrap.bootstrap as bb
from astropy.utils import NumpyRNGContext
with NumpyRNGContext(42):
review_scores = df.scores.values
review_scores_means = bb.mean(review_scores, n_replications=10000)
ci_low, ci_hi = bb.highest_density_interval(review_scores_means)
print(r,'\t', 'low ci:', ci_low, ' high ci:', ci_hi)
ax = sns.distplot(review_scores_means, label = "All bootstrap data")
ax.plot([ci_low, ci_hi], [0, 0], linewidth=10, c='k', marker='o',
label='95% HDI')
ax.set(ylabel='Density', xlabel="1 - 100 Rating",
title="Bootstrap Mean Review Score")
sns.despine()
plt.legend()
plt.show()
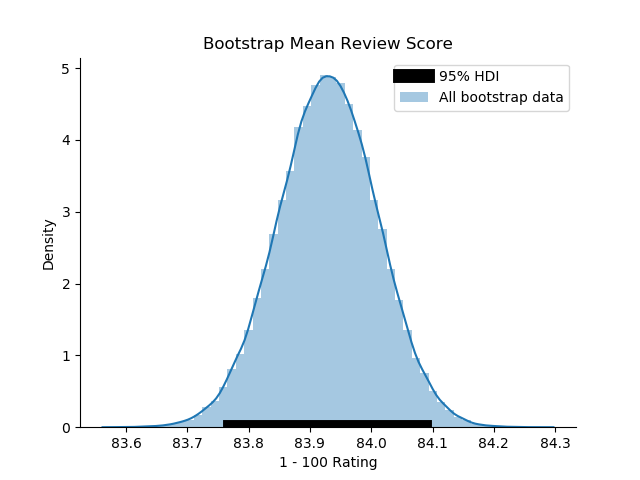
This distribution for the ‘average review’ leads me to a couple of thoughts about the system as a whole: why is the mean so high? Even for the people who use this system like a school grading system: (A: 100-90, B: 89-80, C: 79-70, D: 69-60, F: 59-0), shouldn’t the average be a C? And even if someone didn’t use the system like that and instead utilized every number equally, then wouldn’t we see the average near the median at 50? Maybe people are self constraining their reviews to only good whiskies? Maybe people just straight up suck at reviewing as well (I’m looking at you Mr. Anything Weller Tastes Like Jesus Guy). In order to break that down a bit further, we’ll need explore the weirdness of this dataset.
For starters, out of 14172 reviews, I only found 196 reviews below 50 points. That seems so odd to me. That means something like, you more or less have a 1.38% chance of finding an absolute dog shit whiskey. Surely, that’s impossible, right? On the other hand, ask yourself, have you ever had a whiskey that was so fucking terrible you gave it a sub 50 review? I’m sure everyone mentally can think of ‘the worst whiskey’ they’ve had, but how bad was it really? How does one even rank it that low? “Ah fuck it, I’ll give it a ‘30”? Either way, to have 50% of the available review points only ever utilized by 1.38% of the reviews is ridiculous in any scoring system. Even when we analyze the 196 more thoroughly using the bayesian bootsrap, we can see it’s still a bit strange: most of the mean’s mass is between 31 and 34.
In [78]: scores
Out[78]: array([50.0, 70.0, 91.0, ..., 83.0, 84.0, 74.0], dtype=object)
In [79]: scores.shape[0]
Out[79]: 14172
In [80]: scores[scores < 50].shape[0]
Out[80]: 196
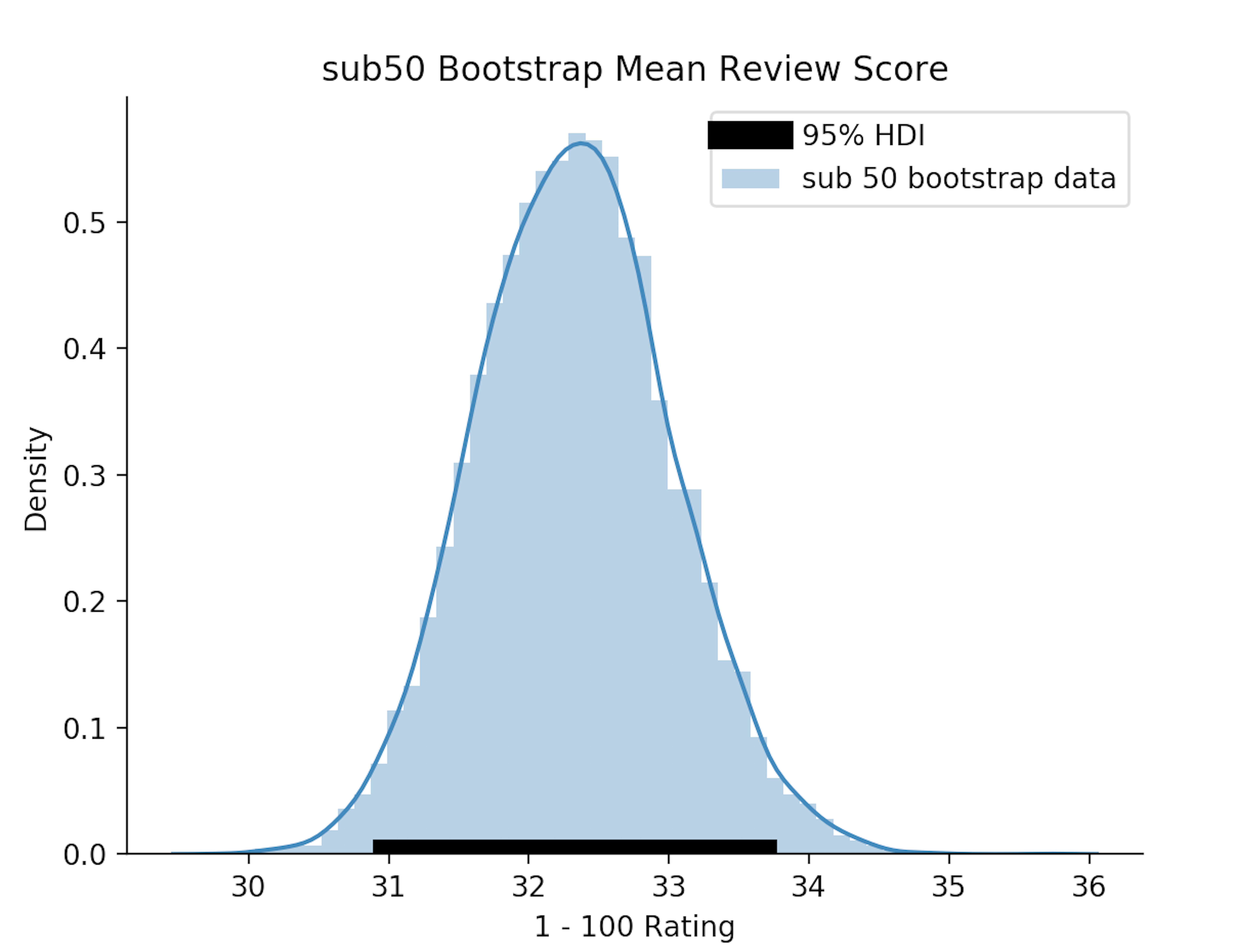
Think about this for a second: in your personal review system, you might be able to distinguish between an 89 and a 90, but can you distinguish between a 29 and a 30? Oh can you? Go fuck yourself.
Top (rather, people with a lot of reviews) Reviewers
Ok cool. So we’ve established that 50% of the scale is worthless. What about the other 50% - how much utility does the remaining 50% actually have? To start, let’s try to take a look at the top (eg, frequent) reviewers’ distirbutional spreads are in comparison with each other. The thought here being that eventually we should start to see mean distributions converge to similar areas of the scale given the amount the individuals contribute. (Note, these reviewers were taken from the reddit Whiskey Review Archive)
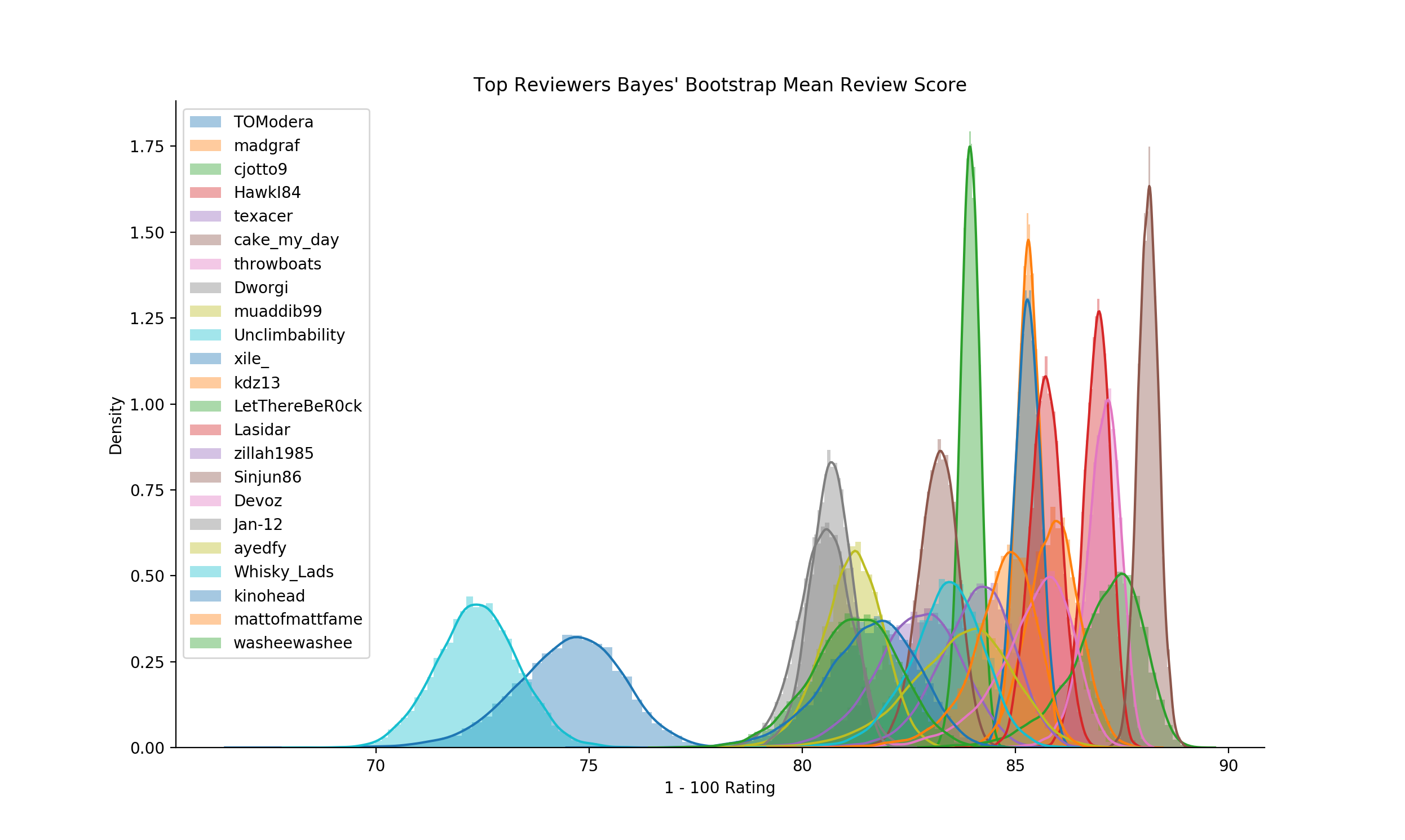
Just for the purpose of argument, I’ve used these same experienced
reviewers and scaled their scores between 0-1 for uniformity. It looks
better, but still so much of each distribution isn’t as close to 0.5 as
I’d personally like to see (which on one hand, we can postulate they
aren’t reviewing trash whiskey and thus skewing their own scores - but
still higher than I’d like to see).
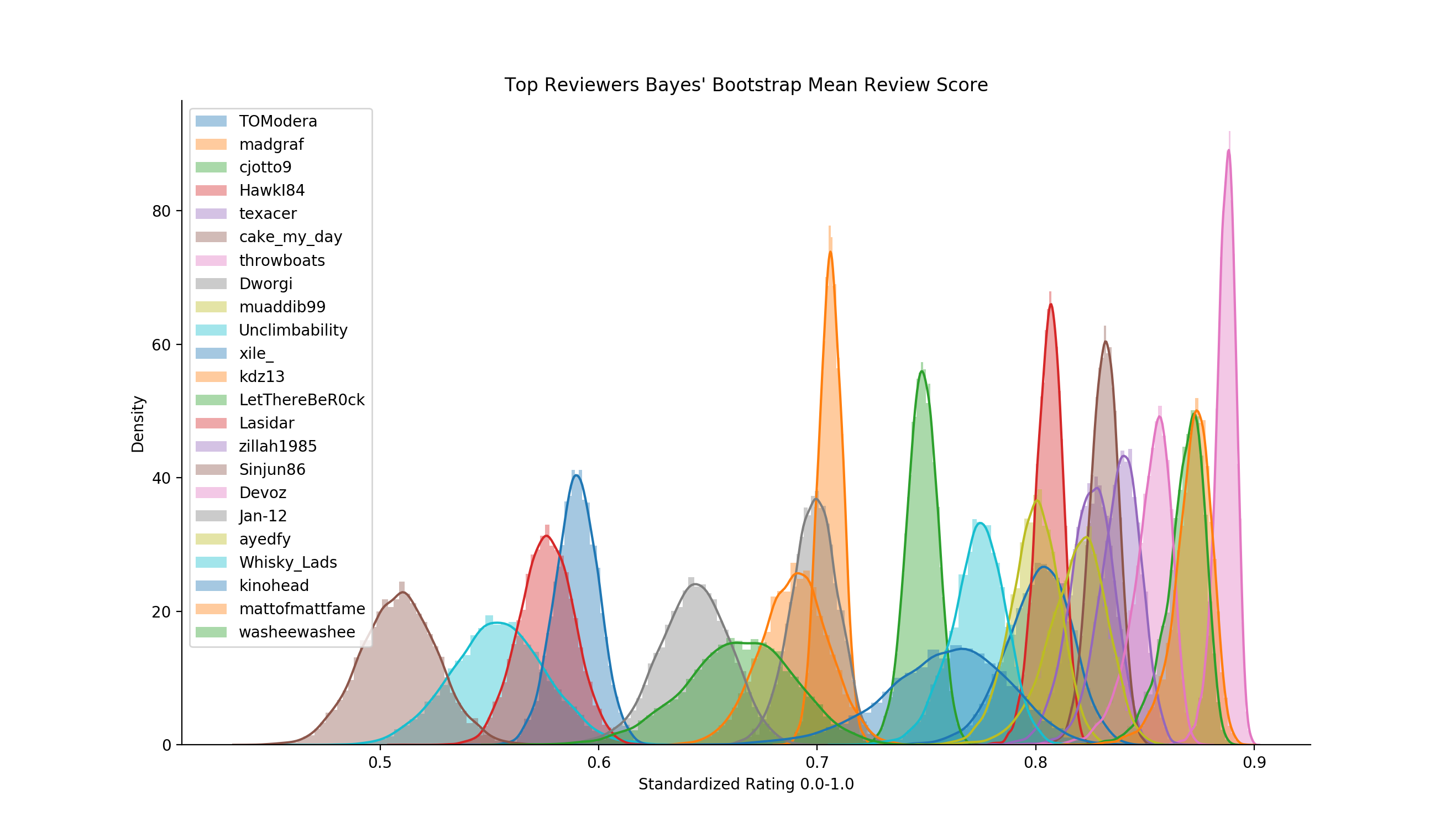
There will always be a difference of opinion on a given whiskey - some will like it - some won’t - but with the amount these individual’s review - and the fact that the whiskies they’re reviewing are from the quality pool - we should still see similar distiributions around a given mean score. If this was a more uniform system, when we apply the same bootstraping technique to the top reviewer’s reviews, we should expect to see a similar distribution (albiet very different at the whiskey level), however, this just isn’t the case.
So what’s the point? These frequent reviewers all review differently. You and I review differently. We all understand how skewed the system currently is. The only thing left to dive into is the the part people hardly pay attention to - the actual fucking review, baby.
Words, words, words
So the scoring is bunk, got it. But what about the review itself? What
can that tell us about the system as a whole? First, let’s analyze the
most basic relationship: the length of review and the sentiment/score of
a given whiskey. Here’s the TL;DR: people use more words when they like
the whiskey, less when they dislike it, and when it’s ‘meh’ - it’s right
there in the middle. Go figure?
Let’s take the above analysis one step further and inspect the
relationship between a rating, the sentiment (the positivity or
negativity of the words
used), and the length
of the review. If we suppose that an average review is anywhere between
~83 and ~84 (the 95% CI), any ‘bad’ review is below 83, and any review
above 84 is ‘good’, we can start to model these reviews using some newer
language modeling techniques. We’ll start by breaking out the data into
three classes: good, bad, average (all based on score, then we’ll take a
pretrained model (this one specifically: Convolutional Neural Networks
for Sentence Classification) that was
trained on the IMDB movie review dataset (meaning it was trained to
learn the sentiment of a movie review on the classic IMDB movie review
dataset) and then we’ll use the model to produce the sentiment polarity
(0-1) of ‘good’, ‘average’, and ‘bad’ whiskey reviews:
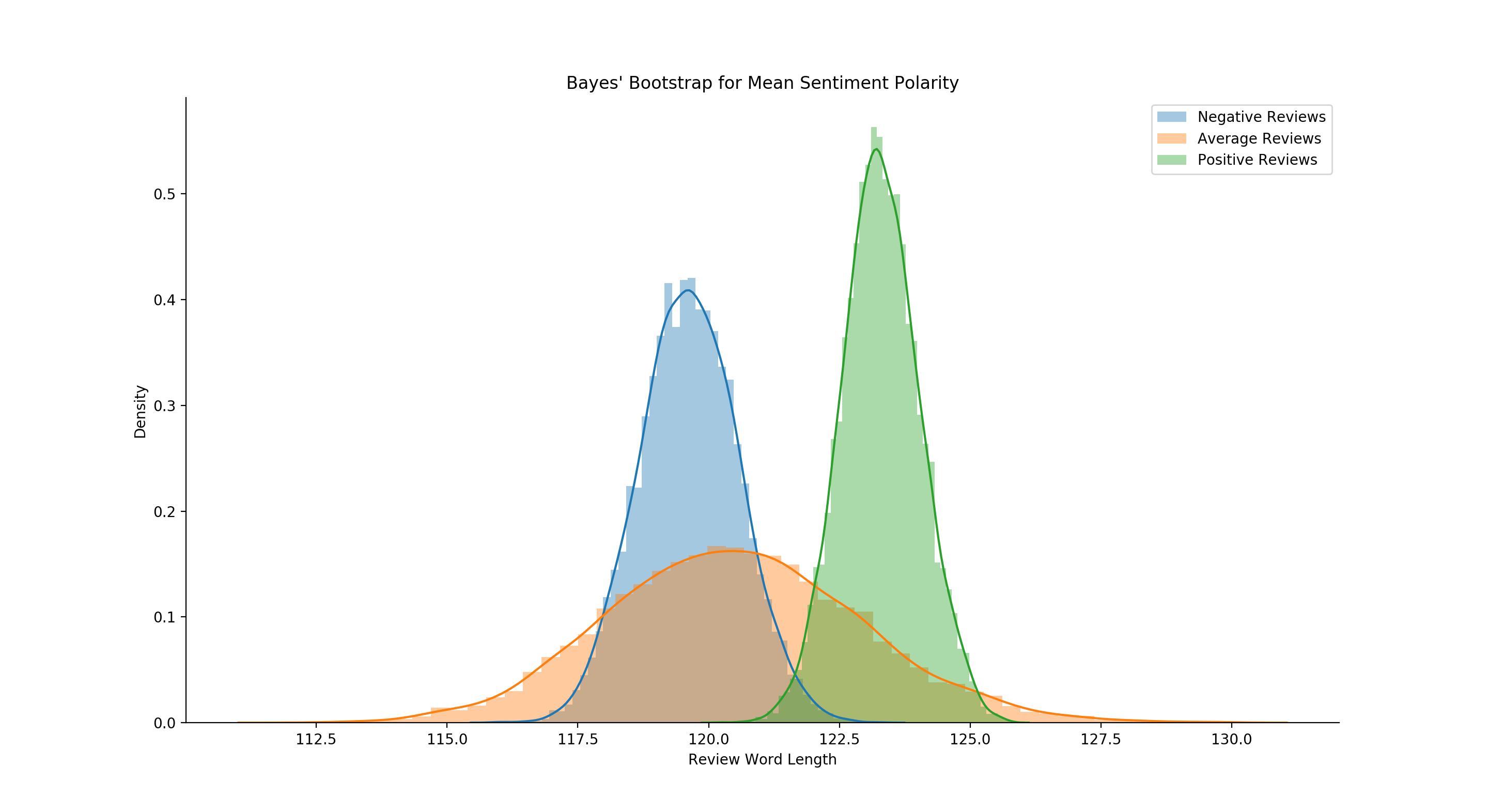
It gives us some quick insight, but it’s not exactly what I’m looking for. We’re seeing too much similarity between the positive and negative reviews. The polarity between negative and positive is obviously different, but it’s not very much. To me, that signals that perhaps the IMDB model isn’t built for the kind of language structure found in reddit whiskey reviews.
In order to make this model more robust, I’m going to force a new model to learn the odd language structure used in whiskey reviews: As a refresher for those outside of whiskey check out my previous blog: The TL;DR: whiskey reviews often contain strings of words - mostly used in a list (taste: word1, word2, word3, etc. palate: word1, word2, etc.) - together to describe the finish, nose, and palate of a given whiskey - where, in the context of a given whiskey review, can mean negative or positive things that are much different than a given word’s usage in general language. For example, ‘young’ as a word, used in everyday language can refer to energy, enthusiam, and happiness (all positive sentiment), but in the context of whiskey can mean that it tastes like gasoline, paint thinner, or bad college memories (all negative sentiment). These thinly veiled differences in language mean that models built for general analysis won’t have the contextual ability to see the review the way a whiskey fan might see the review.
So let’s build and train a model using only the corpus from the whiskey reviews. First, we’ll separate the reviews into three categories: negative reviews (scores under 83), average reviews (scores 83-84), and positive reviews (scores over 84). We’ll assign all negative reviews a 0 and all positive reviews a 1, and we’ll leave the average reviews as our evaluation set (meaning the model won’t touch this data at all). We’ll set aside 30% of all positive and negative reviews and use this held out set to validate our model’s performance (eg, not use that set to update our model’s beliefs about the world - but instead use that data to check and see how well the model is performing - to inform us if we’re training in the correct direction or not). Psuedo-ish code below:
from numpy import array
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils.vis_utils import plot_model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Dropout
from keras.layers import Embedding
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from keras.layers.merge import concatenate
from sklearn.model_selection import train_test_split
# encode a list of lines
def encode_text(text, maxlen):
# integer encode
doc = nlp(text)
vals = tokenizeText(" ".join(clean(doc.text)))
seq = [word_idx[x] for x in vals]
# pad encoded sequences
padded = pad_sequences([seq], maxlen=maxlen, padding='post')
return padded
# define the model
def Model(length, vocab_size):
# channel 1
inputs1 = Input(shape=(length,))
embedding1 = Embedding(vocab_size, 100)(inputs1)
conv1 = Conv1D(filters=32, kernel_size=4, activation='relu')(embedding1)
drop1 = Dropout(0.5)(conv1)
pool1 = MaxPooling1D(pool_size=2)(drop1)
flat1 = Flatten()(pool1)
# channel 2
inputs2 = Input(shape=(length,))
embedding2 = Embedding(vocab_size, 100)(inputs2)
conv2 = Conv1D(filters=32, kernel_size=6, activation='relu')(embedding2)
drop2 = Dropout(0.5)(conv2)
pool2 = MaxPooling1D(pool_size=2)(drop2)
flat2 = Flatten()(pool2)
# channel 3
inputs3 = Input(shape=(length,))
embedding3 = Embedding(vocab_size, 100)(inputs3)
conv3 = Conv1D(filters=32, kernel_size=8, activation='relu')(embedding3)
drop3 = Dropout(0.5)(conv3)
pool3 = MaxPooling1D(pool_size=2)(drop3)
flat3 = Flatten()(pool3)
# merge
merged = concatenate([flat1, flat2, flat3])
# interpretation
dense1 = Dense(10, activation='relu')(merged)
outputs = Dense(1, activation='sigmoid')(dense1)
model = Model(inputs=[inputs1, inputs2, inputs3], outputs=outputs)
# compile
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# summarize
print(model.summary())
return model
vocab_size = 6000
max_review_length=500
train_neg = []
train_neg_labels = []
train_pos = []
train_pos_labels = []
avg = []
for idx in avg_ixs:
doc = nlp(df.iloc[idx[0]].review)
vals = tokenizeText(" ".join(clean(doc.text)))
seq = [word_idx[x] for x in vals]
seq = np.array(seq)
seq[seq>=vocab_size]=0
avg.append(seq)
for idx in bad_ixs:
doc = nlp(df.iloc[idx[0]].review)
vals = tokenizeText(" ".join(clean(doc.text)))
seq = [word_idx[x] for x in vals]
seq = np.array(seq)
seq[seq>=vocab_size]=0
train_neg.append(seq)
train_neg_labels.append(0.0)
for idx in like_ixs:
doc = nlp(df.iloc[idx[0]].review)
vals = tokenizeText(" ".join(clean(doc.text)))
seq = [word_idx[x] for x in vals]
seq = np.array(seq)
seq[seq>=vocab_size]=0
train_pos.append(seq)
train_pos_labels.append(1.0)
x_train = train_neg + train_pos
y_train = train_neg_labels + train_pos_labels
x_train = pad_sequences(x_train, maxlen=max_review_length, padding='post')
train_X, test_X, train_y, test_y = train_test_split(x_train, y_train)
model = define_model(max_review_length, vocab_size)
# fit model
model.fit([train_X,train_X,train_X], np.array(train_y), validation_data = ([test_X,test_X,test_X], test_y), epochs=10, batch_size=16, shuffle=True)
# save the model
"""
Train on 10058 samples, validate on 3353 samples
Epoch 1/10
10058/10058 [==============================] - 89s 9ms/step - loss: 0.4426 - acc: 0.8152 - val_loss: 0.3112 - val_acc: 0.9344
Epoch 2/10
10058/10058 [==============================] - 86s 9ms/step - loss: 0.1613 - acc: 0.9550 - val_loss: 0.1131 - val_acc: 0.9588
Epoch 3/10
10058/10058 [==============================] - 86s 9ms/step - loss: 0.0482 - acc: 0.9805 - val_loss: 0.1400 - val_acc: 0.9508
Epoch 4/10
10058/10058 [==============================] - 86s 9ms/step - loss: 0.0275 - acc: 0.9876 - val_loss: 0.2266 - val_acc: 0.9168
Epoch 5/10
10058/10058 [==============================] - 84s 8ms/step - loss: 0.0203 - acc: 0.9906 - val_loss: 0.1317 - val_acc: 0.9627
Epoch 6/10
10058/10058 [==============================] - 86s 9ms/step - loss: 0.0180 - acc: 0.9925 - val_loss: 0.1632 - val_acc: 0.9603
...
"""
sentiment = model.predict([test_X, test_X, test_X])
neg_sentiment = sentiment[test_y<1.0].flatten()
pos_sentiment = sentiment[test_y>0.0].flatten()
avg_sentiment = []
for idx in range(len(avg)):
seq = avg[idx]
seq = np.array(seq)
seq[seq>=vocab_size] = 0
seq_padded = pad_sequences([seq], maxlen=max_review_length, padding='post')
out = model.predict([seq_padded, seq_padded, seq_padded])[0][0]
avg_sen
with NumpyRNGContext(42):
bad_sent_means = bb.mean(neg_sentiment, n_replications=10000)
avg_sent_means = bb.mean(avg_sentiment, n_replications=10000)
pos_sent_means = bb.mean(pos_sentiment, n_replications=10000)
# ci_low, ci_hi = bb.highest_density_interval(m)
# print(r,'\t', 'low ci:', ci_low, ' high ci:', ci_hi)
# ms.append([m, ci_low, ci_hi])
ax = sns.distplot(bad_sent_means, label = "Negative Reviews")
ax = sns.distplot(avg_sent_means, ax=ax, label = "Average Reviews")
ax = sns.distplot(pos_sent_means, ax=ax, label = "Positive Reviews")
#ax.plot([ci_low, ci_hi], [0, 0], linewidth=10, c='k', marker='o',
# label='95% HDI')
ax.set(ylabel='Density', xlabel="Sentiment Polarity",
title="Bayes' Bootstrap for Mean Sentiment Polarity".format(r))
sns.despine()
plt.legend()
plt.show()`
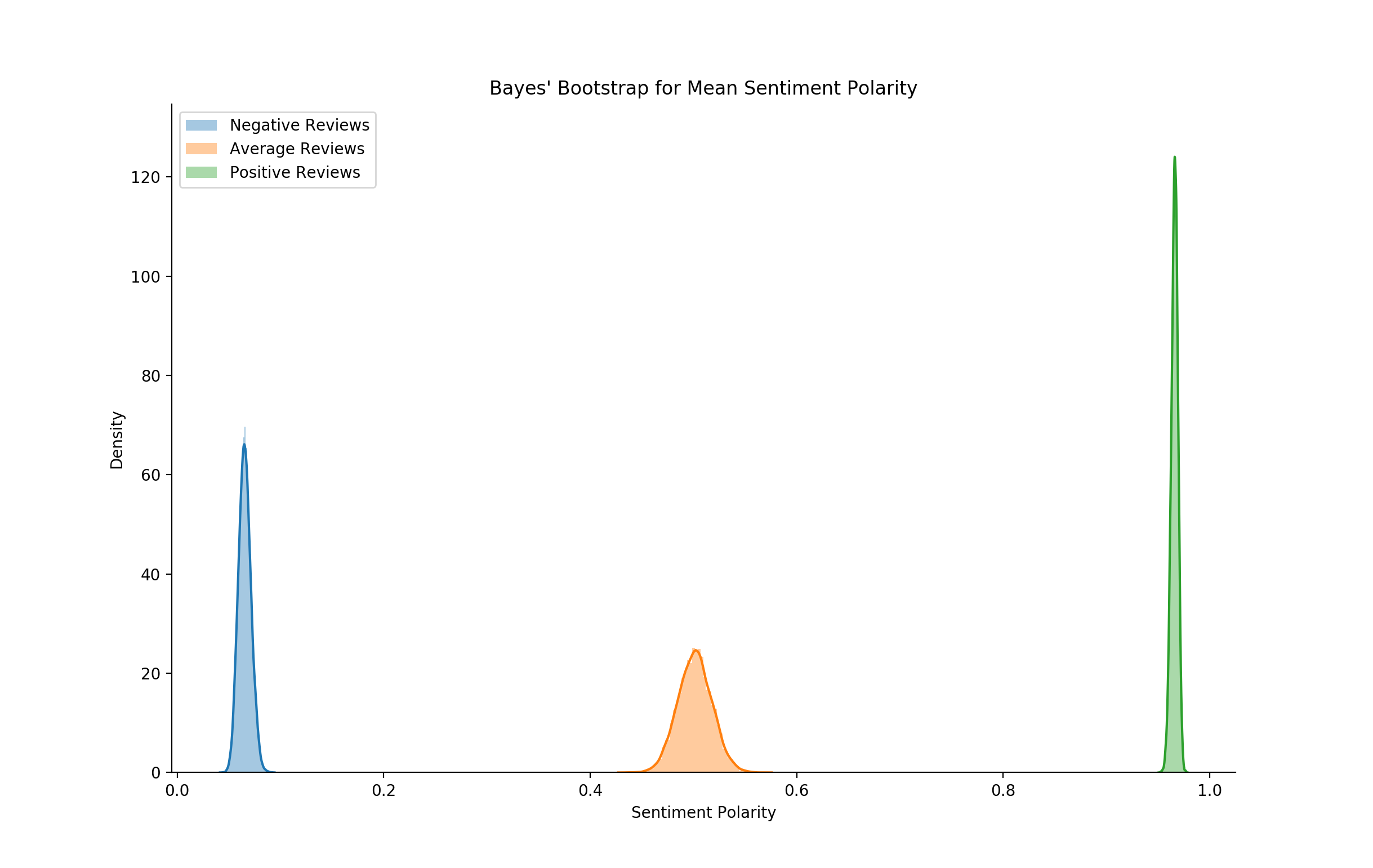 Not only does the model have 96% accuracy on our validation set, it also
puts our held out ‘average’ reviews right smack dab in the middle of
sentiment - confirming a bit that our mean value choice was a fairly
good one and that the language we’re using to review a given whiskey
already does most of the heavy lifting! So what does this mean for
scores? Well here’s the thing, if you were to leave out the score
completely, the review text alone would indicate with ~96% accuracy the
1-100 review score. Basically, the review’s text (choice of words) is
more or less equivalent to the score.
Not only does the model have 96% accuracy on our validation set, it also
puts our held out ‘average’ reviews right smack dab in the middle of
sentiment - confirming a bit that our mean value choice was a fairly
good one and that the language we’re using to review a given whiskey
already does most of the heavy lifting! So what does this mean for
scores? Well here’s the thing, if you were to leave out the score
completely, the review text alone would indicate with ~96% accuracy the
1-100 review score. Basically, the review’s text (choice of words) is
more or less equivalent to the score.
A (kinda) New System
Here’s my big whopper of an idea: a text review plus a binary thumbs up or thumbs down. Plain and simple. We’re already writing reviews anyway, and because we’ve already established that the review itself is indicative of the ‘score’, just let the word choice do all the hard work and add a little blurb about whether or not you liked it. A simple 0 or
- It’s going to be a bit harder for some people. You’re actually going to have to have an opinion and not hide your dislike behind an abomination of a score, but I believe in you. And if you’re not sure, just fucking take a couple extra days force yourself to make a tough decision instead of leaving any ambiguity to the reader.
Think about it here for a second, switching to binary review systems is not some grand original idea. In fact, major companies like StichFix and Neflix have switched their entire rating systems to a binary system much in part because of the issues and problems expressed here. Considering that I work in research, one of the fundemental tenents is piggybacking as much as you can off the hardwork of others. Especially off incredibly massive research teams who spend their entire day deciding on the pros and cons of systems such as binary ones.
Lastly, I can’t prove it, but I think removing the current 1-100 scores would force reviewers to think more critically about a given whiskey. And perhaps enforcing a culture of critical thinking might have stopped the madenss that is today’s bourbon market - even though that’s a quite a stretch - it sure would be nice. Can’t you just imagine some asshole combing through recent reviews trying to find ‘the best whiskey to buy and hoard’ and being thwarted simply because he has to read? It’s my wet dream.
I have a problem with your (not) new idea
Question: That’s great and all, Matt. But I want to rank my whiskies, how am I supposed to do that with this scoring system?
Answer: A score isn’t necessarily a rank. When scoring, we have a habit of pulling in all this external information to attempt to represent a ‘did I enjoy this’ score and it’s ‘how does it compare to everything else’ ranking in one scaler value. I think it’s important to concentrate on the moment and give a whiskey an individual score; forget about that random Brora you had, you’re not there, you’re here in the moment - concentrate on that and if must rank something from best to worst - then the reality is nothing is stopping you. But trying to cram multidimensional meaning into one value is where we start to have odd problems that I’ve tried to outline above.
Question: Now that Pappiz and Wild Turkey 101 share the same rating, how am I supposed to know which new hot whiskey to spend my money on and/or even which whiskey is the best?
Answer: Welp, no one could ever answer that question for you in the first place without you sampling them for yourself. And as for which whiskey to spend your money on, why don’t you do what you currently do and read the reviews, brosef stalin. Or check out something like this tool I created: http://wrec.herokuapp.com/ to help you figure out the components of given whiskies that you might enjoy.
Question: How am I supposed to brag if all my instagram pictures are just ‘ones’ now?
Answer: You’ll figure it out, you sexy influencer, you.
Question: So nothing will change?
Answer: Probably not. But maybe the money I just dumped into MGPI might do better, hopefully.
Question: So seriously, why even write this article?
Answer: Maybe, just maybe, we can make it harder for Jefferson’s to figure out what barrel of trash to put their whiskey in next.